- Echtzeit-Sprachkommunikation
Eine AI-basierte Echtzeit-Sprachkommunikationsanwendung mit extrem niedriger Latenz. Durch die Integration von großen Modellen, Sprach-zu-Text, Sprachsynthese und anderen KI-Technologien wird eine effiziente Erfassung, Verarbeitung und Übertragung von Audio- und Videodaten ermöglicht, um eine schnelle und natürliche Echtzeitkommunikation zwischen Nutzern und großen Modellen zu gewährleisten.
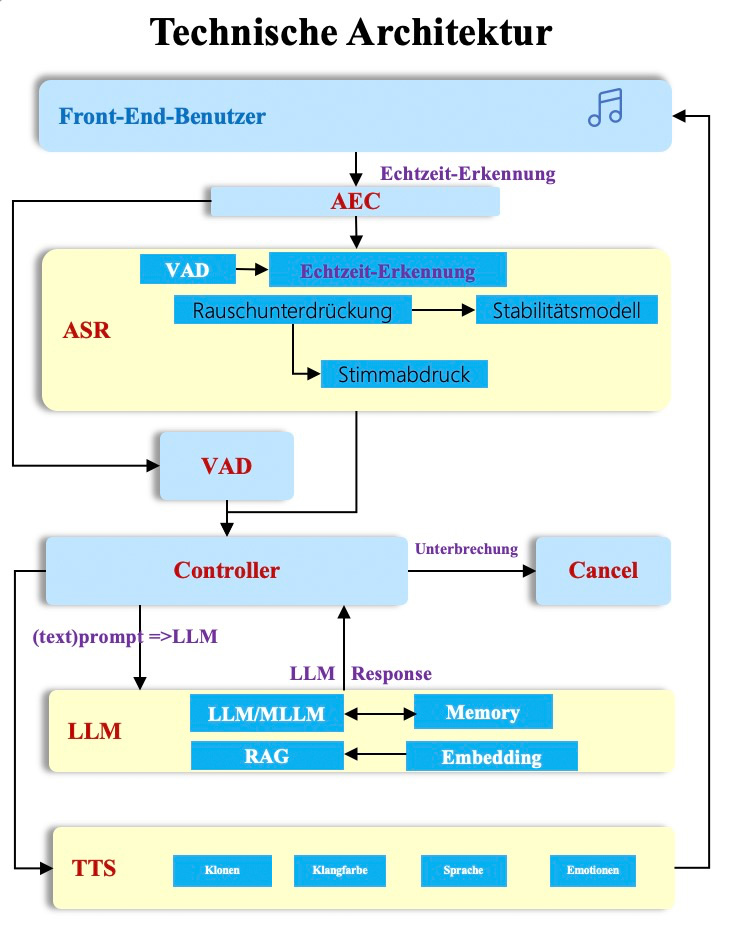
- Intelligente Unterbrechung: Unterstützt Full-Duplex-Kommunikation und Audio-Frame-gesteuerte Sprachaktivitätserkennung (VAD), ermöglicht Unterbrechungen und sorgt so für eine natürlichere Kommunikation.
- Endgeräte-Nebenrauschunterdrückung: Durch das RTC SDK wird eine Audio-Nebenrauschunterdrückung in komplexen Umgebungen realisiert, die Hintergrundgeräusche und Musik reduziert und die Genauigkeit von Sprachunterbrechungen erhöht.
- Extrem niedrige Latenz: Durch vollständige End-to-End-Datenverarbeitung wird die gesamte RTC+ASR+LLM+TTS-Verzögerung auf 2 Sekunden reduziert.
- Widerstandsfähigkeit gegen schwache Netzwerke: Durch intelligente Anbindung und Cloud-basierte RTC-Optimierung wird bei komplexen und schwachen Netzwerkbedingungen eine geringe Latenz und zuverlässige Übertragung gewährleistet, wodurch Fehler aufgrund von verlorenen Wörtern im Modellverständnis vermieden werden.
- Schnelle Integration, einfache Implementierung: Eine One-Stop-Integration ermöglicht es Unternehmen, einfach Standard-OpenAPI-Schnittstellen zu verwenden, um die benötigten Dienste wie Sprach-zu-Text (ASR), Sprachsynthese (TTS) und große Modelle (LLM) zu konfigurieren und schnell AI-basierte Echtzeit-Interaktionen zu implementieren.
- Multiplattform-Unterstützung: Unterstützt iOS, Android, Windows, Linux, macOS, Web, Flutter, Unity, Electron und WeChat Mini Program, um unterschiedlichen Anwendungsanforderungen gerecht zu werden.
Durch RTC wird eine effiziente Erfassung von Audio- und Videodaten, benutzerdefinierte Verarbeitung und ultra-niedrige Latenzübertragung realisiert. In der Cloud bietet das System ein intelligentes Audio- und Videoverarbeitungsmodul, das Funktionen wie Audio 3A, AI-Rauschunterdrückung und Frame-Screenshot umfasst, um die Auswirkungen von Umgebungsgeräuschen und Geräteleistung auf das dialogorientierte KI-Erlebnis zu minimieren. Darüber hinaus wird eine tiefe Integration von Sprach-zu-Text (ASR), Sprachsynthese (TTS), großen Sprachmodellen (LLM) und Wissensdatenbanken (RAG) durchgeführt, um den Prozess der Umwandlung von Sprache in Text und Text in Sprache zu vereinfachen und starke KI-gesteuerte Dialog-, natürliche Sprachverarbeitungs- und Multimodal-Interaktionen zu ermöglichen. Dies unterstützt die schnelle Realisierung von Echtzeit-Sprachkommunikation und multimodalen Interaktionen zwischen Nutzern und Cloud-basierten großen Modellen.





 ICP-Einreichung:备案中
ICP-Einreichung:备案中